Submit Jupyter Notebooks as Jobs
warning
This is a new feature still in beta so please leave some feedback and report any issues.
There is one known issue with the Update Job Definition and Resume job definition which is related to Nebari-Workflow-Controller issue, captured here. The current workaround for those who need to update (or pause) your job definitions, is simply to delete the current job definition and create a new one as and when needed.
A common task that many Nebari users have is submitting their notebooks to run as a script or to run on a predefined schedule. This is now possible with Jupyter-Scheduler, a JupyterLab extension that has been expanded and integrated into Nebari. This also means that you can view the status of the jobs by vising the <nebari-domain>/argo endpoint.
The idea of notebook jobs is useful in situations where you need no human interaction, besides submitting it as a job, and the results can be efficiently saved to your home directory, the cloud or other similar storage locations. It is also useful in situations where the notebook might run for a long time and the user needs to shut down their JupyterLab server.
info
If you're curious why shutting down your JupyterLab server (and associated JupyterLab extensions) doesn't kill or stop your running Jupyter-Scheduler jobs, this is because the Nebari team extended Jupyter-Scheduler to use Argo-Workflows as it's backend; details can be found here.
Jupyter-Scheduler is included by default in the base Nebari JupyterLab image and can be used with any conda-store environment available to the notebook author.
Install papermill
note
When using a conda-store environment, please ensure that the papermill package is included.
Configure Groups
note
Only users in the admin or developer groups will have access to create notebook jobs. For more information regarding users and groups, please visit How to configure Keycloak.
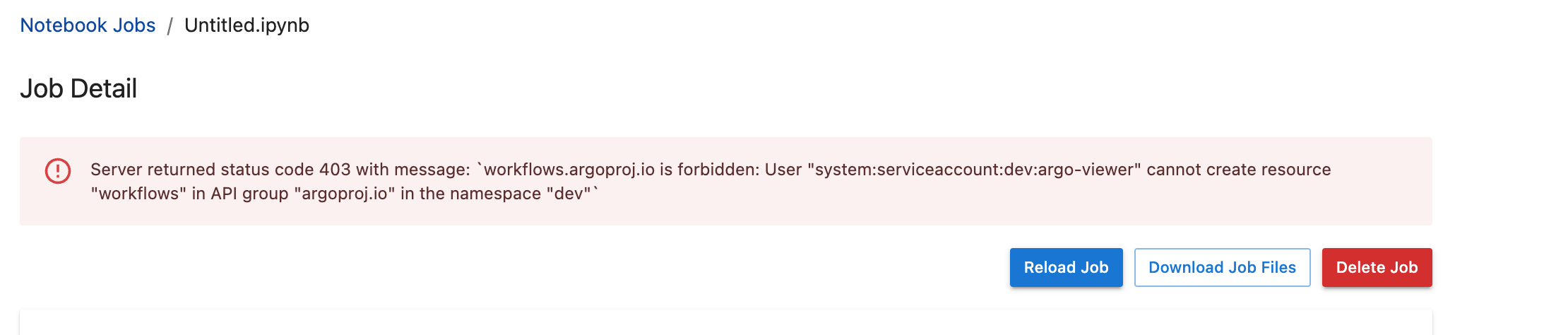
If your user is not part of one of the mentioned groups, you might see an error like this one when clicking on the job details:
Server returned status code 403 with message: 'workflows.argoproj.io is forbidden: User "system:serviceaccount:dev:argo-viewer" cannot create resource "workflows" in API group "argoproj.io" in the namespace "dev"
The mentioned groups should also automatically set argo-server-sso Client
Roles. To check, go to the Role Mappings tab in Keycloak and see if you have
argo-admin or argo-developer listed as Effective Roles.
If you did configure the groups but still see this error, it's possible that changes are not visible in JupyterLab. Terminate the JupyterLab server, log out/in via Keycloak, then start the server and try again.
Submitting a Notebook as a Jupyter-Scheduler Job
To submit your notebook as a Jupyter-Scheduler Job, simply click the Jupyter-Scheduler icon on the top of your notebook toolbar.
![]()
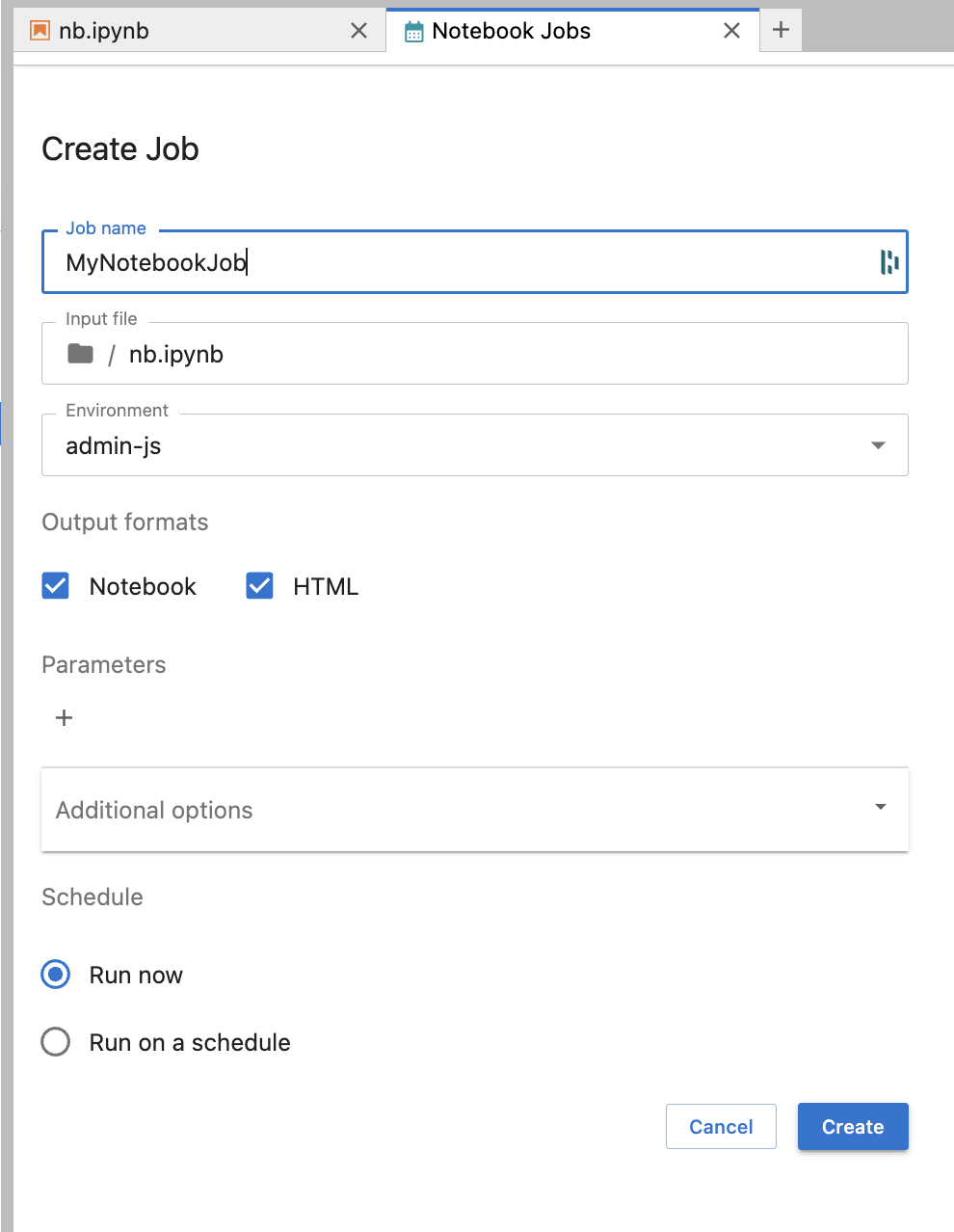
This will open the Jupyter-Scheduler UI. From here you can specify:
- the notebook job name
- the input file the use (this will default to the file from which the icon was clicked)
- the environment to run the notebook with
- add environment variables via the
Parameterssection
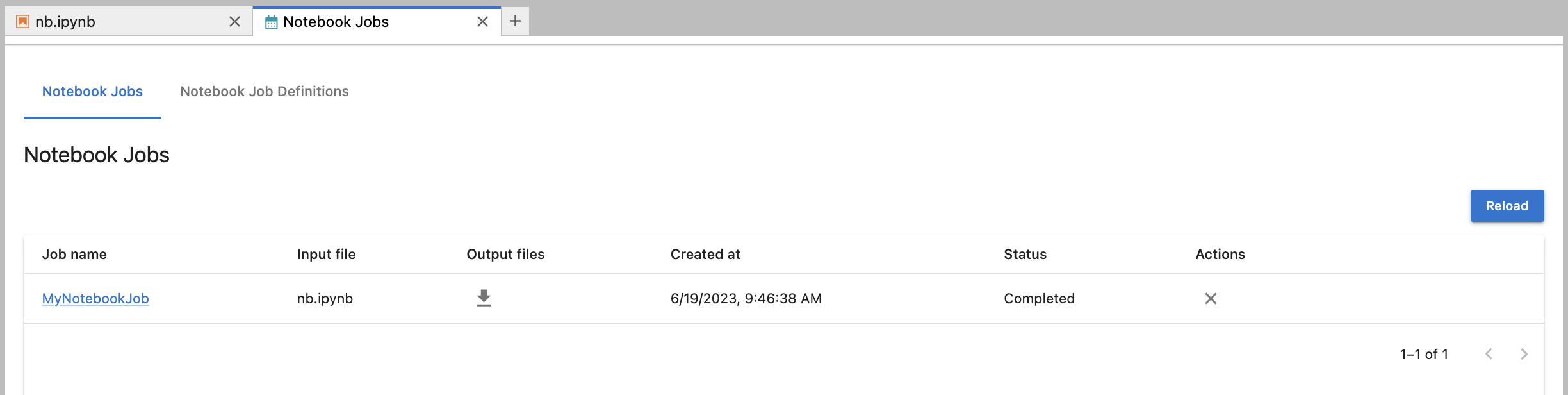
Once created, the status and output of the notebook job can be viewed from the Jupyter-Scheduler UI:
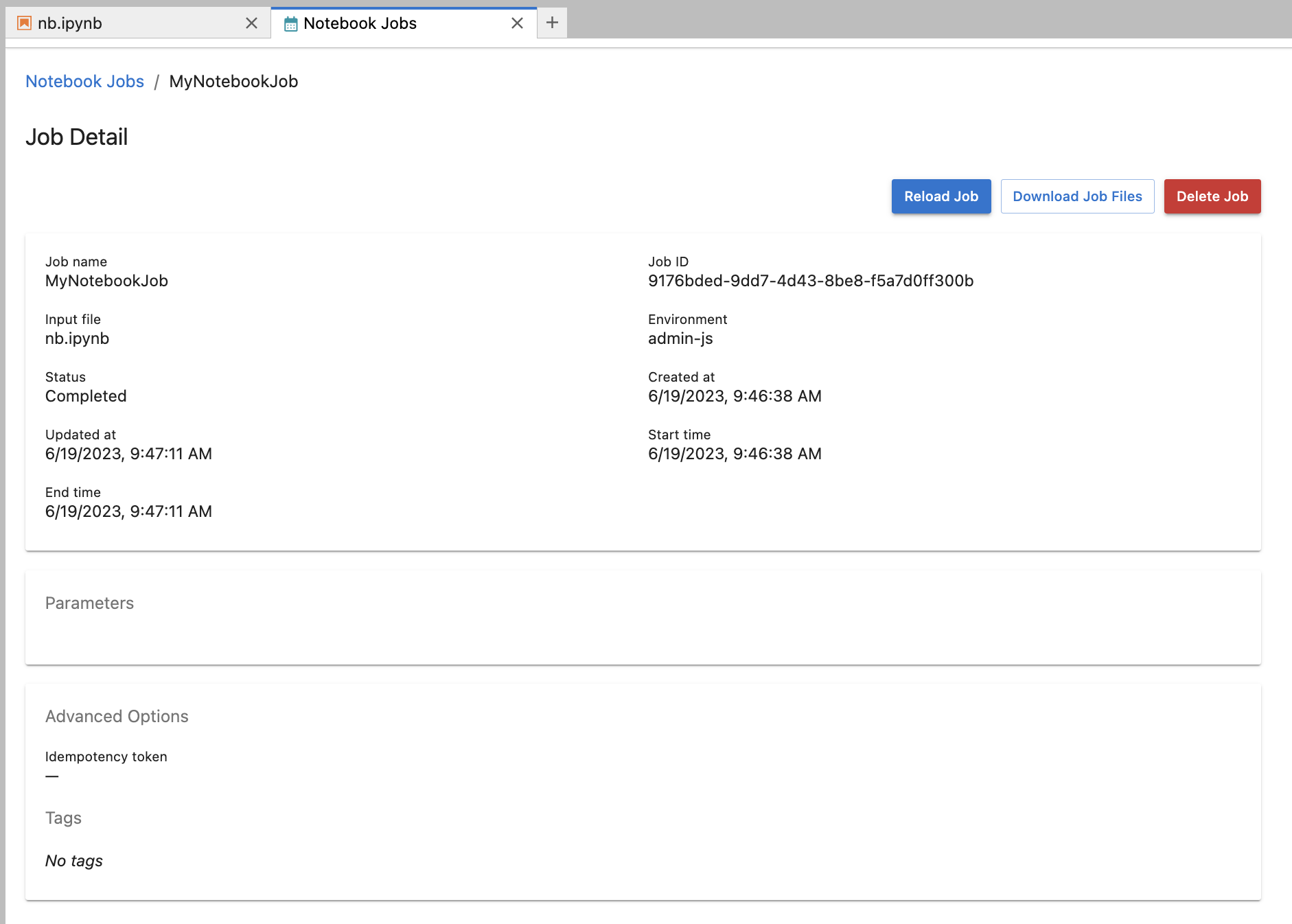
Click on the notebook job name to view more information about the job. From here, you can view:
- the job ID
- when the job was created
- the start time and end time
info
As mentioned above, the notebook job will run as an Argo-Workflows workflow. This means these jobs (workflows) are viewable from the Argo-Workflows UI at <nebari-domain>/argo. The name of the workflow is prefixed with job-<job-id>.

All associated workflows have a TTL (time-to-live) set to 600 seconds. This means that regardless of whether or not your workflow was successful, it will be deleted after 10 mins. The downside is that those logs are now gone, that said, the upside is that the workflow no longer consumes compute resources once deleted.
Submit Jupyter Notebooks to run on a schedule
The other way notebooks can be run is on a specified schedule, Jupyter-Scheduler refers to these are "Job Definitions". After selecting the Jupyter-Scheduler icon at the top of the notebook, select "Run on a schedule" and then define the schedule the notebook should be run on. There is also an option to specify the time zone.
tip
You can check crontab.guru which is a nifty tool that tries to translate the schedule syntax into plain English.
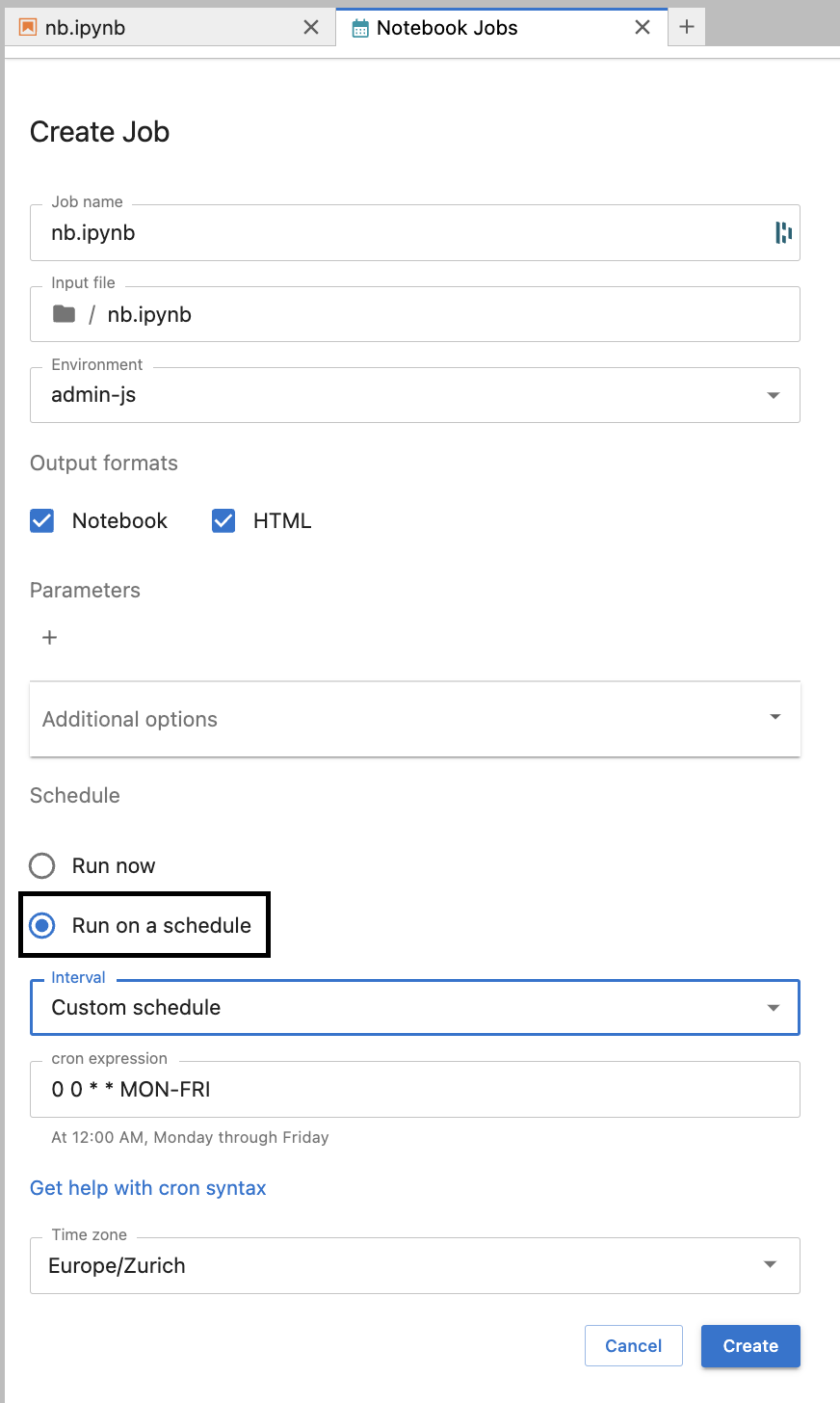
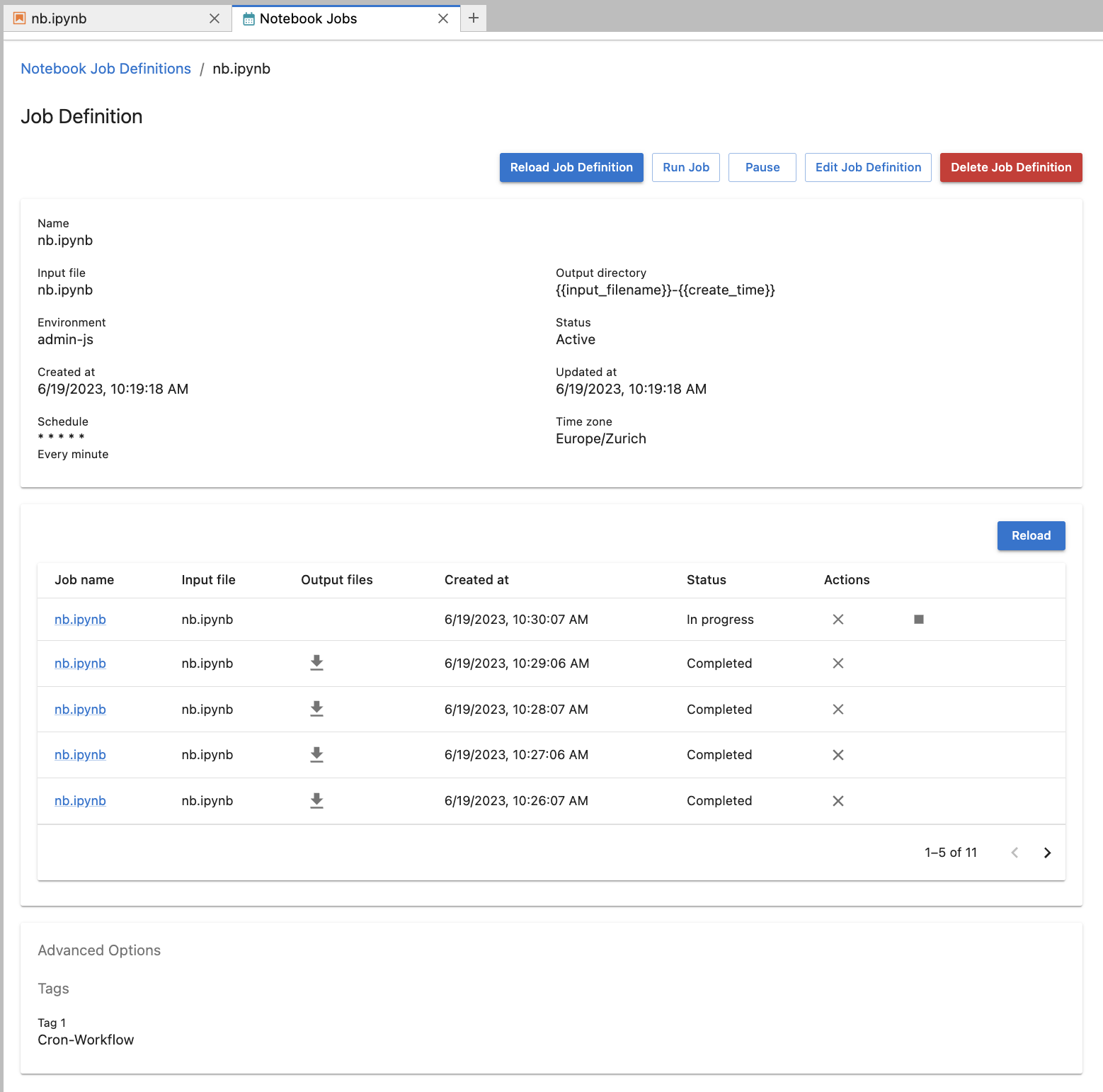
When a job definition is created, a new job is created at each time interval specified by the schedule. These created jobs can be inspected like a regular notebook job. From here you can:
- delete the job definition
- pause the job job definition
- view details such as the status of the job definition
- view the list of notebook jobs created from this job definition
- view the tags (by default all job definitions are tagged with
Cron-Workflow)
info
Unlike a regular notebook job, job definitions create Argo-Workflows cron-workflows (workflows that run on a schedule). This cron-workflow in turn creates workflows at each time interval specified by the schedule. Another difference is that the workflow names are prefixed with job-def-<job-definition-id>.

warning
Notebook jobs that run on a schedule will run indefinitely so it's the responsibility of the job creator to either delete or pause the job if then they are no longer needed.
Debugging failed jobs
Occasionally notebook jobs will fail to run and it's helpful to understand why.
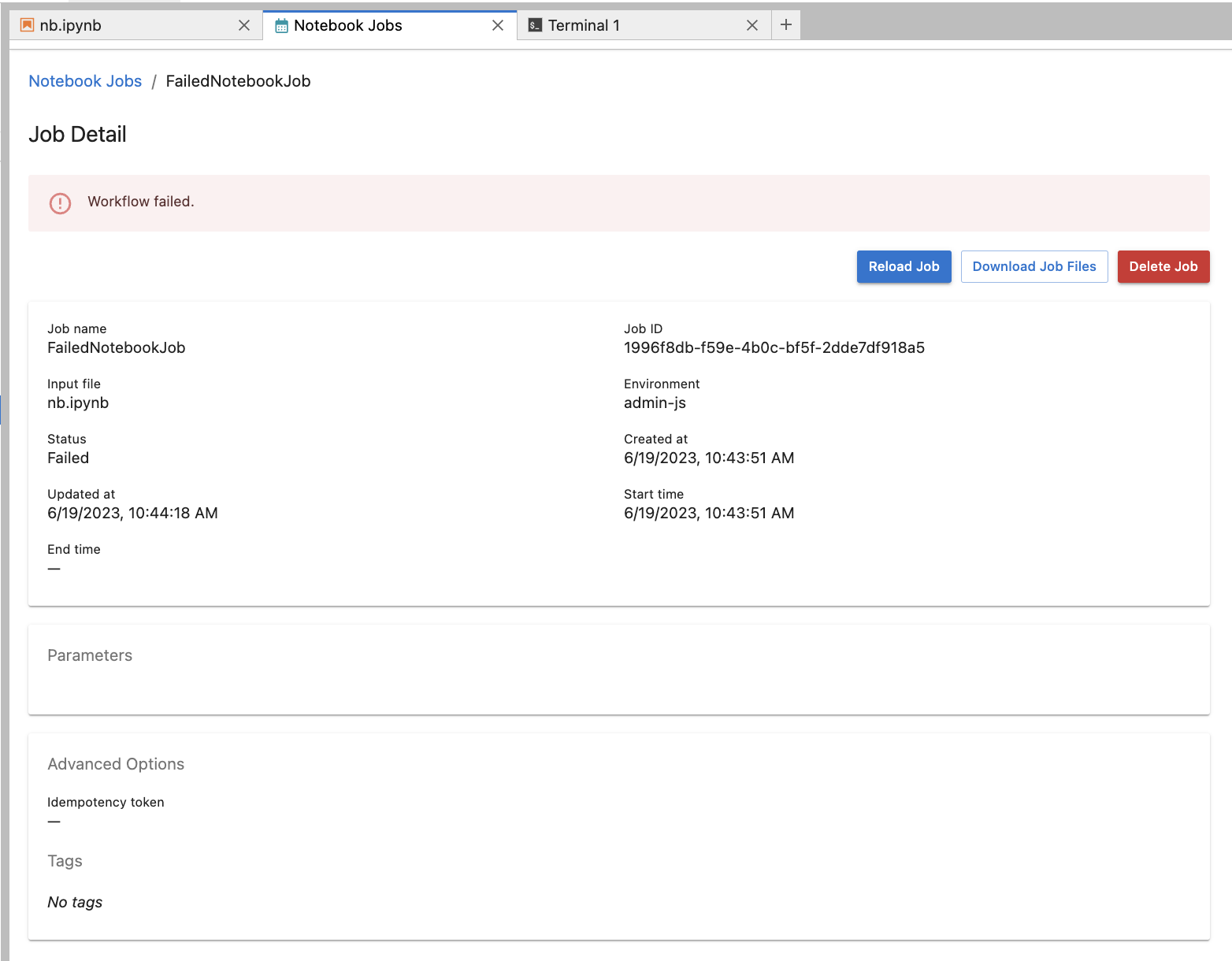
If there is an issue with the notebook code itself, viewing the notebook job logs will help the user get a better idea of what went wrong. These are the steps to get the logs:
- Document the job ID
- Launch a terminal session
- Navigate to
~/.local/share/jupyter/scheduler_staging_area - Find the folder that corresponds to the job ID that failed
- Open (or
cat) theoutput.ipynbto view the notebook as it was run
info
Notebook job details can also be viewed from the <nebari-domiain>/argo UI.
Lastly, if the job fails without writing to this scheduler_staging_area, or the job status is stuck in In progress mode for an extended period of time, have an administrator try and view the specific logs on the user's JupyterLab server pod or on the workflow pod itself.